Explaining P-Value to your Grandmother
26 Mar 2019

Why you should try to explain p-value to your grandmother
On today’s lecture “STATISTICAL DATA ANALYSIS”, professor came up with an interesting question:
“How would you explain p-value to your grandmother?”
The context and implication behind this question was that statisticians should be able to explain and deliver statistical terms to ordinary people. The explanation should be concise, easy and must include idea of statistical significance, without using terms such as distribution, alpha. If you try to explain p-value using statistical and mathematical terms…

Apparently, that’s the face she would make.
Even Scientists are confused with the concept of p-value
In fact, many people (even scientists and researchers) misinterpret the concept of statistical significance. Many journals and research papers provide their evidence using p-value but most of these interpretations turned out to be wrong: results were irreproducible, or p-value was selectively chosen for their explanation.
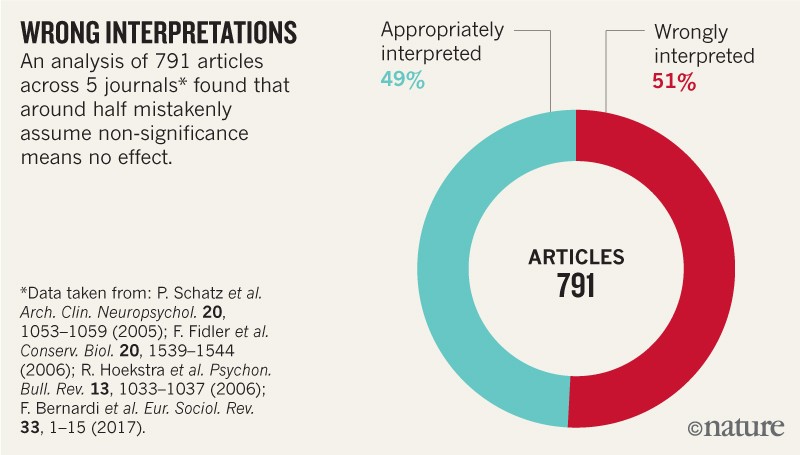
source: https://www.nature.com/articles/d41586-019-00857-9
In this sense, statisticians should be able to double check whether their understanding is correct or not. The best way to do this is trying to teach the concept to other people. Tutoring or teaching can be a way of developing one’s own understanding and establishing confidence to their knowledge. This is probably why the professor suggested students to try to explain p-value to their grandmother.
One Way of Explanation
According to definition of p-value by American Statistical Association (a.k.a ASA), p-value is “the probability that statistical summary of the data would be equal to or more extreme than its observed value”. To put this in easier words, I would tell my grandmother like this:
p-value is the chance of what you saw or experienced is completely different from the actual or real thing. You can make use of this chance to question the existing knowledge involving the real thing.
Of course this statement omits assumptions of p-value, I believe it contains the abstract notion of what p-value is…
Types of Neural Network (TBU)
25 Feb 2019
Intro
Neural Networks used in Deep Learning were inspired by the biological neural networks that form the brains of animals.
Although the concept was developed in the 1940s, the infrastructure and computing powers that enabled development of deep learning and studies of Artificial Intelligence appeared much later.
With the explosive enhancement of computing power and data storage capacities, Deep Learning with Neural Network started to prove its performance. Since then, Neural Network, A.I, Deep Learning became the buzz words.
Types of Neural Networks
There are numerous types of Neural Networks depending on its purpose and complexity of problems to solve. The diagram below summarizes almost complete chart of Neural Network structures that are being used and studied. In this post, I will only cover some of the most widely used or known structures: __Feedforward Network__, __Recurrent Neural Network__, __Convolutional Neural Network__.

1. Feedforward Neural Network
Also known as Multi-layer Perceptrons, this is the simplest form of Artificial Neural Network, where all information are processed in one direction. There are input layers, one hidden layer and output layers. There are no back loops that changes the flow.

Recurrent Neural Network (RNN)
Convolutional Neural Network (CNN)
References
- https://towardsdatascience.com/the-mostly-complete-chart-of-neural-networks-explained-3fb6f2367464
- https://www.learnopencv.com/understanding-feedforward-neural-networks/
Important Terms in Deep Learning (TBU)
15 Feb 2019
Terminology List
- Weights
- Hidden Layer
- Gradient
- Exploding Gradient Problem
- Vanishing Gradient Problem
- Activation Function
- ReLU (Rectified Linear Units)
- Sigmoid Function
- Cost Function
- Backpropagation
- Learning Rate
- Batch, Epoch, Iteration
- Dropout
- Pooling, Padding
Weights
Hidden Layer
Gradient
Exploding Gradient Problem
Vanishing Gradient Problem
Activation Functions
ReLU
Sigmoid Function
Cost Function
Backpropagation
Learning Rate
Batch, Epoch, Iteration
Dropout
Pooling, Padding
References
- https://www.analyticsvidhya.com/blog/2017/05/25-must-know-terms-concepts-for-beginners-in-deep-learning/
Confusion Matrix
08 Jan 2019
Among the ways of measuring the performance of prediction by n machine learning or statistical analysis, there is Confusion Matrix(or Error Matrix).
The Confusion Matrix is a type of contingency table(or Pivot Table), where data are presented in cross tabulated format. It displays the interrelation betwee two variables and often used to find interactions between those variables.
True Positive, True Negative, False Positive, False Negative
If you are making a prediction about a binary case, four types of results can be expected:
| Prediction |
Actual Value |
|
| 0 |
0 |
» True Negative (TN) |
| 0 |
1 |
» False Negative (FN) |
| 1 |
0 |
» False Positive (FP) |
| 1 |
1 |
» True Positive (TP) |
To facilitate understanding or memorizing the concepts above, the naming of TN, FN, FP, TP is based on the prediction.
- If the prediction is right, it is True
- If the prediction is 0, it is Negative
- And if the prediction is 0 and right, it is True Negative
Terminology and Measurements from Confusion Matrix
Recall=Sensitivity=Hit Rate=True Positive Rate(TPR)
Summarizes how well the model predicts or classifies the positive(1) data. The value is calculated by dividing the whole actual positive data by correctly predicted positive data. (True Positive)
Specificity=Selectivity=True Negative Rate(TNR)
Specificity is similar to Recall or Sensitivity, but retrieving the rate of correctly predicted negative data (True Negative) to the whole actual negative data.
Fallout=False Positive Rate(FPR)
This concept refers to falsely predicted rate of predicting actual positive data negatively.
Miss Rate=False Negative Rate(FNR)
This concept refers to falsely predicted rate of predicting actual negative data positively.
Precision=Positive Predictive Value(PPV)
Precision is about being precise with the prediction. It tells how likely the predictive positive will be correct.
Accuracy(ACC)
Percentage of getting the predictions right. This summarizes how well (accurate) the model predicts or classifies.
R.O.C Curve (Receiver Operating Characteristics)

-
The ROC curve has Specificity(False Positive Rate) and Sensitivity(True Positive Rate) as the two axis.
-
The higher the curve is above y=x graph, the better the performance of a model is.
-
However, ROC is an illustrated graph of FP and TP. And it is difficult for comparing models in some cases where the difference is not intuitively noticable. Thus, AUC (Area under Curve) is used as a parameter.
-
The ROC AUC value is area of the ROC curve. The highest value is 1, and the better the model, the higher the AUC value is.
Precision Recall Plot (PR Graph)

- Precision-Recall plot, as its name presents, uses precision and recall to evaluate model.
- Generally, it uses recall as horizontal axis and precision on the vertical axis in 2-Dimensional plotting.
- The PR Graph is used when the distribution of labels used in classification is highly unbalanced; when the number of positive cases overwhelms the number of negative cases.
- Just like the ROC curve, it uses AUC as a parameter to evaluate the model.
F1-Score (F score when $\beta$=1 )
\[F_{\beta} = \frac{(1+\beta^2)(Precision * Recall)}{(\beta^2*Precision*Recall)}\]
- In order to measure performance of a model with AUC of ROC or PR, many calculations are required in various throughputs.
- F1 Score is used to express the performance of a model in a single number.
- When $\beta$ = 1, the F score is called F1 Score and it is a widely used metric for model evaluation.
Python Code Example
from sklearn.metrics import classification_report as clr
from sklearn.metrics import confusion_matrix as cm
# Confusion Matrix (TP,FP,TN,FN)
print(cm(test_y # List of Actual Values
, pred_y)) # List of Predicted Values
# Classification Report (Precision, Recall, F1-Score)
print(clr(test_y # List of Actual Values
, pred_y)) # List of Predicted Values
Gradient Boosting
18 Dec 2018
Boosting
In Machine Learning, Boosting refers to creating a stronger and more accurate learner by combining weak and simple learners. In other words, it is a technique of producing a stronger model by ensembling weak models. The principle that lies behind this concept is that integration of models may complement problems that individual models face.
Gradient Boosting
Loss/Cost Function
Simply Saying, the learning (training) of machine is achieved by finding parameters that minimizes loss function.
Loss function (or cost fuction) is a function that maps the difference between estimated value and real value.
Of course, the objective of using loss function is to minimize it; a method to achieve optimization.
Gradient Descent
Gradient Descent is one of the methods used to find the optimal parameters when solving minimization problem of loss function.
By calculating the partial derivative of the loss function with respect to parameters, gradient (or slope) can be calculated. Since the gradient tells how much the output of a function changes by the changing the input, it can be used to direct the model to reach its local minimum.
References
https://en.wikipedia.org/wiki/Gradient_boosting
http://4four.us/article/2017/05/gradient-boosting-simply
