
What is GAN?
05 Apr 2019
Introduction
Since April 1st, I started working with a startup company named Crevasse A.I, which aims to develop a customized A.I generator of copy-right free images. As the company tries to utilize GAN technology, I had to understand and develop modules based on these deep learning theories.
As I would like to keep track of my studies and works involving A.I, I will be posting summaries of research papers and github repositories that I worked on.
But first, let’s start with GAN, which became the most standardized methodology of unsupervised learning.
Supervised vs Unsupervised Machine Learning
The ultimate objective of machine learning (deep learning is a subset of machine learning) is to predict future with given data. The difference between unsupervised and supervised machine learning depends on the existence of labels (Let’s set aside Reinforment Learning in this post).
Since supervised machine learning requires labeled dataset or data with answers, the amount of usuable data is strictly limited as it takes resources to create large amount of labeled data.
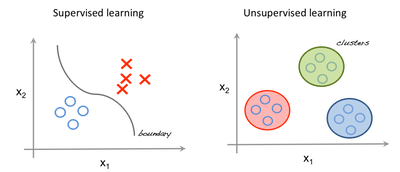
source: towardsdatascience.com
On the other hand, unsupervised learning trains without labels, allowing machines to find answers by themselves. In this sense, many scholars and A.I experts regard unsupervised machine learning as the leading technology for the next-generation. And the most representative and widely studied unsupervised model is Generative Adververisal Network (GAN)
GAN
As it name implies, GAN is composed of two models: Generative Model($G$) and Discriminitive Model ($D$). While Generative Model generates a new data, Discriminitive Model discriminates the generated data whether it is fake or real. The two model competes (adverses), until a certain point where Discriminitive Model cannot distinguish fake data from real data.

Generative Adversarial Network (GAN)
source: https://www.researchgate.net/figure/Generative-Adversarial-Network-GAN_fig1_317061929
In order to understand GAN fully, knowledge on probability distribution is a requisite. GAN treats all data as a random variable with a certain probability distribution. The Generative Model ($G$) tries to approximate to the real probability distribution of data. if this is accomplished, it will produce real-like-fake data based on the approximated real probability distribution, and the Discriminitive Model ($D$) would not be able to distinguish the fake from the real by throwing a meaningless probability: 50%

GAN over its training
black dotted line: real data probability distribution
green dotted line: probability distribution made by G
blue dotted line: probability distribution of D
source: IAN GOODFELLOW GAN paper
GAN in Mathematical Context

Mathematical Expression of GAN
-
$x\sim p_{data}(x)$: data [$x$] sampled from a real probability distribution[$ p_{data}(x) $]
- $z$ : latent vector (a vector that can explain the data in a latent space; a reduced dimension)
- $z \sim p_z(z)$ : sampled data [$z$] from a random noise that generally adopts Gaussian Distribution
- $D(x)$: Discriminator (if true = 1 , false = 0)
- $G(z)$ : Generator
- $D(G(z))$ : Result of discrimination of generated data (if true = 1 , false = 0)