
Topic Modeling and Latent Dirichlet Allocation
08 Oct 2018
Topic Modeling
The objective of topic modeling is very self explanatory; discovering abstract “topics” that can most describe semantic meaning of documents. It is an integrated field of machine learning and natural language processing, and a frequently used text-mining tool to discover hidden semantic structures in the texts. Topic modeling can help facilitating organization of vast amount of documents and find insights from unstructured text data.
LDA (Latent Dirichlet Allocation)
LDA is one of the graphical models used for topic modeling. LDA is a generative statistical model that posits specific probability of word appearance in accordance to a specific topic. The image below best explains how LDA works.
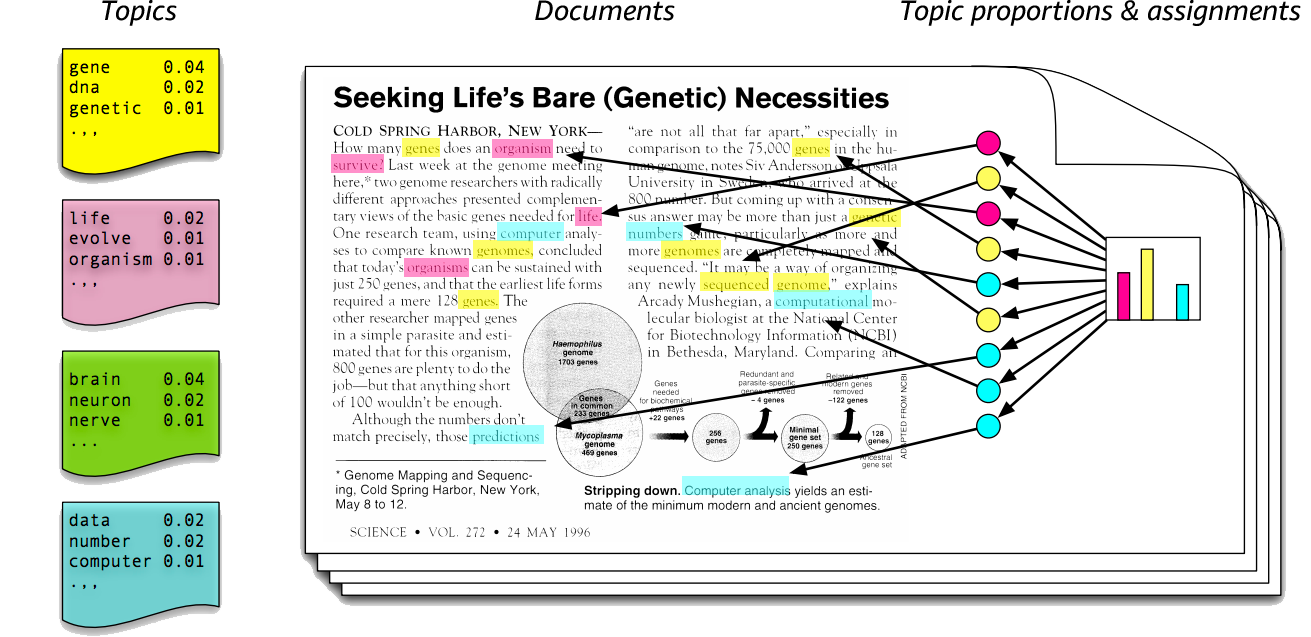
The key part of LDA lies in the right part of the diagram, “Topic proportions and Assignments”. LDA views documents as a mixture of various topics and each topic consists of a distribution of words. LDA has several assumptions:
- number of N words are decided by Poisson distribution
- from number K topic sets, document topics are decided by Dirichlet distribution
- each word \(w_{i}\) in the document is generated by following rules:
- pick a topic in accordance to the multinomial distribution sampled above
- generate the word using the topic in accordance to the multinomial distribution of the words in that topic
Model

- \(\alpha\) is the parameter of the Dirichlet prior on the per-document topic distributions,
- \(\beta\) is the parameter of the Dirichlet prior on the per-topic word distribution,
- \(\theta_{m}\) is the topic distribution for document \(m\),
- \(\varphi_{k}\) is the word distribution for topic \(k\),
- \(z_{mn}\) is the topic for the \(n\)-th word in document \(m\), and
- \(w_{mn}\) is the specific word.