
Information Extraction Methodologies
31 Dec 2019
In the previous post, I explained the process and importance of Information Extraction (IE). In this post, detailed methodologies and approaches to IE will be covered.
The methodologies can be classified into three learning based approaches:
-
Rule Learning based
-
Classification based
-
Sequential Labeling based
Traditionally, all of these approaches are considered as a supervised learning because labeled data is required to train the model for extracting information.
Rule Learning based Method
This approach is self-explanatory: we define a set of rules or patterns to extract information. In general, the rule learning based methods have three ways of learning:
- Dictionary-based (Pattern-based)
- Rule-based
- Wrapper induction
Dictionary-based (Pattern-based) approach creates a predefined template (dictionary) and use it to extract required information from the new texts. The core issue to this approach is how to detect patterns and construct the dictionary. Extraction takes place when the dictionary finds a triggering word (usually a verb) and tries to locate the target entities by identifying its pattern.
For example, let’s say we want to extract information of primary habitats of different animals. We can include pattern “noun-verb-target” in our dictionary to extract information from the following sentence: “Bats live in a cave”. In this case, the triggering word would be “live”. Because “live” was in the sentence, the model would search for noun and target in the sentence and retrieve “cave” as the primary habitat for “Bats”.
Rule-based approach use several general rules rather than dictionary. The rules are related to syntaxes and semantics of the words delimiting the targeted entity. Usually two types are rules are included in the model: tagging rules and additional rules for correction or improvement. Tagging rules may include part-of-speech tagging, name entity and type of the word. Using this information, a specific word can be acknowledged as a target for extraction if it matches all the pattern.
For example, let’s reuse the example from the Dictionary based approach. In this case, we will create a table of rules as below:
| Word | Part of Speech (POS) | Kind | Name Entity | Action |
|---|---|---|---|---|
| Bears | Noun | Word | Animal | |
| live | Verb | Word | ||
| Cave | Noun | Word | Place | Habitat |
Using the rules above, we can extract information by parsing following sentence: “Dragons live in a cave”. Because the word “cave” is a noun, word and place, it matches our rule in the table above. Thus, we can extract the habitat “cave”. However, we need to update our rules or generalize the rules to extract “Dragons” because the word is not in the rule table.
Wrapper induction is for semi-structured documents like html texts. Using the tag names or html, specific information can be retrieved from a constructed web page. For example, let’s say we have a html code as below:
<tbody>
<tr></tr>
<td class="title">Star Wars</td>
<td class="ratings">5.3</td>
<tr></tr>
<td class="title">Jumanji 2</td>
<td class="ratings">6.6</td>
<tr></tr>
<td class="title">Frozen 2</td>
<td class="ratings">8.7</td>
<tr></tr>
<td class="title">Knives Out</td>
<td class="ratings">9.1</td>
</tbody>
It is not hard to see that title of the movies are wrapped between <td class="title"> and </td>, while the ratings are in bewteen <td class="ratings"> and </td>. Using the wrappers and its characteristics (<td> and class namein this case) we can extract information from the html above.
The Rule Learning based Methods are intuitive, easy to understand and implement. However, require tedious manual labors of tagging and labeling the data. Largely pertaining to this characteristics, it is regarded as “a dead-end technology in academia while largely adopted by commercial vendors”.2
Classification based Method
IE can be viewed as a classification problem; setting a boundary with two classifiers (starting classifier, end classifier) to locate an entity. Let’s look at the example below:

The words in the sentences are parsed as tokens and each words are classified by the starting classifier and ending classifier. Then, the result can be combined and entities of interest can be extracted.
There numerous machine learning classifiers available: Support Vector Machines, Random Forest Classifiers, Naive Bayes Classifier, etc. The classification based approach is about how to view or cast the IE problem as a classification problem. Choosing a classifier can follow after that.
Sequential Labeling based Method
Simlar to the Classification based method, we can view IE task as a sequantial labeling. Text data can be seen as a sequence of labeled tokens. Unlike other two methods, sequential labeling method allows the model to include context of dependencies between the words of interest. The sequential labeling method differs on how the conditional probability is computed since the objective is to find a label sequence $y$ that maximizes the conditional probability, $p(x \vert y)$.
Among the various methods, Conditional Random Fields are an important and widely incorporated model in the field of IE.
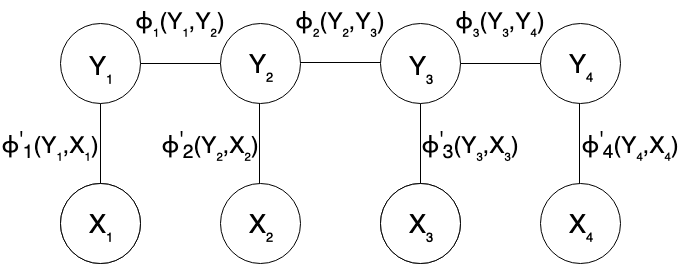
Conditional Random Field (CRF)
CRF is a type of discriminative undirected probabilistic graphical model. The important feature that CRF has is that it can include the information of “context” into the model, using dependencies between the tokens.
The definition follows:
Let $G = (V,E)$ be a graph such that $\mathbf{Y} = (Y_v)_{v \in V}$ so that $\mathbf{Y}$ is indexed by the vertices of $G$. Then $(\mathbf{X},\mathbf{Y})$ is a conditional random field when the random variables $Y_v$, conditioned on $\mathbf{X}$ obey the Markov property with respect to the graph:
$p(\mathbf{Y}_v \vert \mathbf{X},\mathbf{Y}_w, w\neq v) = p(\mathbf{Y}_v \vert \mathbf{X},\mathbf{Y}_w, w \sim v)$ where $w \sim v$ means that $w$ and $v$ are neighbors in $G$ 3
References & Citations:
1 Tang, Jie, et al. “Information extraction: Methodologies and applications.” Emerging Technologies of Text Mining: Techniques and Applications. IGI Global, 2008. 1-33.
2 Chiticariu et al., “Rule-Based Information Extraction is Dead! Long Live Rule-Based Information Extraction Systems!”, Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, 2013. 827–832
3 Lafferty, J., McCallum, A., Pereira, F. (2001). “Conditional random fields: Probabilistic models for segmenting and labeling sequence data”. Proc. 18th International Conf. on Machine Learning. Morgan Kaufmann. pp. 282–289.